
Operator Monitoring and Health Checks for Tangle Blueprint Nodes
Tangle is a programmable infrastructure network where operators run modular services called Blueprints and get selected for paid jobs based on on-chain health signals. Two core mechanisms govern whether your operator stays in rotation: on-chain heartbeats submitted through the OperatorStatusRegistry, and quote freshness (5-minute default lifetime, 1-hour protocol maximum). Fall behind on either and the protocol silently skips you. Jobs stop arriving with no error message and no notification.
Getting a Blueprint operator online is the easy part. Keeping it selected for jobs is where most operators quietly fail. The thresholds governing selection live in on-chain registry contracts and in protocol constants spread across multiple config files. This post pulls those into one place and explains how they interact, so you can build monitoring that catches problems before they cost you revenue.
Note: Tangle’s protocol is not yet live on mainnet. The contracts and configurations described here reflect the current codebase and design. Specific parameters may change before launch.
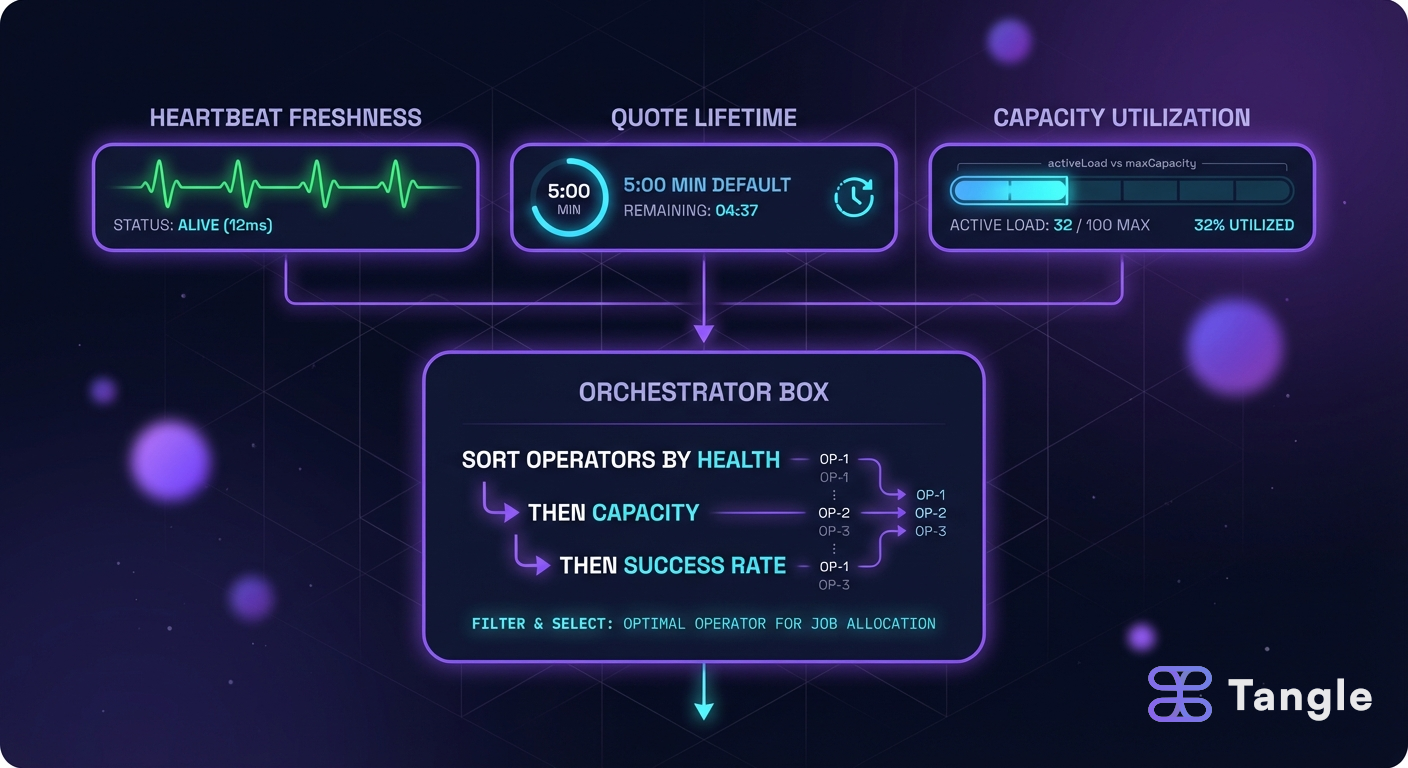
Heartbeats: the on-chain pulse check
Operators prove liveness by submitting heartbeats on-chain through the OperatorStatusRegistry. Each heartbeat carries a service ID, blueprint ID, status code, and an optional metrics payload. The registry tracks four values per operator per service:
lastHeartbeat: timestamp of the most recent submissionconsecutiveBeats: how many in a row without a missmissedBeats: accumulated misseslastMetricsHash: hash of the most recent metrics payload
Two functions expose the result: isHeartbeatCurrent() returns whether the latest heartbeat is within the configured interval, and isOnline() combines heartbeat freshness with status code to give a binary liveness signal.
Status codes and what they mean
The protocol defines five status codes in the StatusCode enum:
| Code | Name |
|---|---|
| 0 | Healthy |
| 1 | Degraded |
| 2 | Offline |
| 3 | Slashed |
| 4 | Exiting |
The _processHeartbeat function in OperatorStatusRegistry uses these codes to determine operator state. A heartbeat with a status code of Healthy (0) resets missedBeats to zero and increments consecutiveBeats. Other codes are processed according to the contract’s internal logic and may affect whether isOnline() returns true.
Each service configures its own HeartbeatConfig with an interval (how often heartbeats are expected), a maxMissed threshold (how many misses before consequences), and an optional customMetrics flag. This is per-service, not global, so an operator running three different blueprints might have three different heartbeat cadences.
Querying your own state
You can inspect your operator’s on-chain health at any time:
// Binary liveness check
registry.isHeartbeatCurrent(serviceId, operatorAddr);
registry.isOnline(serviceId, operatorAddr);
// Full state inspection
registry.getOperatorState(serviceId, operatorAddr);
// Returns: lastHeartbeat, consecutiveBeats, missedBeats, status, lastMetricsHash
// Individual metric values (if customMetrics enabled)
registry.getMetricValue(serviceId, operatorAddr, "cpu_utilization");The getMetricDefinitions(serviceId) call returns the schema for a service’s expected metrics, including name, minValue, maxValue, and whether each metric is required. If your blueprint defines required metrics and you stop submitting them, the registry logs the violation on-chain.
Job selection and operator health
Beyond on-chain heartbeats, the orchestrator that routes jobs to operators will use its own health assessment when selecting operators. The design targets a system where job outcomes, success rates, and available capacity all factor into selection priority.
The general selection model works like this: operators with better health signals and more available capacity get priority for new jobs. Operators that fail jobs or fall behind on heartbeats get deprioritized or removed from rotation entirely.
The specific thresholds and selection algorithms are still being finalized. What is certain: on-chain heartbeat status and quote freshness are hard requirements. If isOnline() returns false or your quotes are expired, you will not be selected regardless of any other factor.
Quote lifetimes: the tuning surface nobody talks about
When a user requests a job, the operator’s pricing engine generates a quote. That quote has a lifetime, and getting the lifetime right matters more than most operators realize.
Quote validity duration is the number of seconds a price quote remains acceptable to the protocol after generation. The default is 5 minutes (quote_validity_duration_secs: 300 in operator.toml). The protocol enforces a hard cap of 1 hour (MAX_QUOTE_AGE = 1 hours in ProtocolConfig.sol). Anything between those bounds is your call.
Why shorter isn’t always better
A short quote lifetime (say, 30 seconds) limits your price exposure. If the cost of the resources you’re committing changes between quote generation and job execution, a shorter window reduces the risk that you’re locked into a stale price. For operators dealing with volatile token pricing, this matters.
But short lifetimes create user friction. The user needs to receive the quote, review it, sign the payment, and submit the request before the quote expires. On a congested network, that flow can easily take more than 30 seconds. An expired quote means a failed request and a retry.
Why longer isn’t always better
A long quote lifetime (approaching the 1-hour cap) is comfortable for users but risky for operators. Resource costs can shift, token exchange rates can move, and you’re committed to the quoted price for the entire window.
Practical guidance
For most operators, the 5-minute default works well for stablecoin-denominated services where price volatility is low. Consider adjusting in these scenarios:
- Volatile token pricing: Drop to 60-120 seconds. Accept the increased retry rate as a cost of price accuracy.
- Long user flows: If your users are interacting through UIs with multiple confirmation steps, extend to 10-15 minutes. Monitor your expired-quote rate.
- High-value jobs: Shorter is safer. A 1-hour quote on a job that costs several hundred dollars in compute creates real exposure.
Keep your quote server address current on-chain via updateOperatorPreferences on the ITangleOperators interface. A stale address means quotes can’t be fetched at all, which is worse than any lifetime misconfiguration.
The pricing engine under the hood
Quotes aren’t arbitrary numbers. The pricing engine runs automated benchmarks on your hardware when a service activates (ServiceActivated event), measuring CPU, memory, storage, network, and GPU performance. Results are cached locally by blueprint ID.
The quote formula is: Base Resource Cost x Time Multiplier x Security Commitment Factor.
Resource pricing is configured per-blueprint in your operator.toml:
[blueprint.resources]
cpu = { count = 8, price_per_unit = "0.001" }
memory = { count = 16384, price_per_unit = "0.00005" }
storage = { count = 1024000, price_per_unit = "0.00002" }The pricing engine’s full config controls benchmark behavior and the quote server:
database_path = "./data/price_cache"
benchmark_duration = 60
benchmark_interval = 1
keystore_path = "./data/keystore"
rpc_bind_address = "127.0.0.1"
rpc_port = 9000
rpc_timeout = 30
rpc_max_connections = 100
quote_validity_duration_secs = 300If rpc_max_connections is too low for your traffic, quote requests will queue and potentially time out, which looks identical to an offline quote server from the user’s perspective. For operators expecting high request volume, bumping this above the default 100 is worth doing.
The degradation cascade: signals before slashing
Operators don’t get slashed out of nowhere. There’s a predictable cascade, and every stage produces signals you can catch if you’re watching.
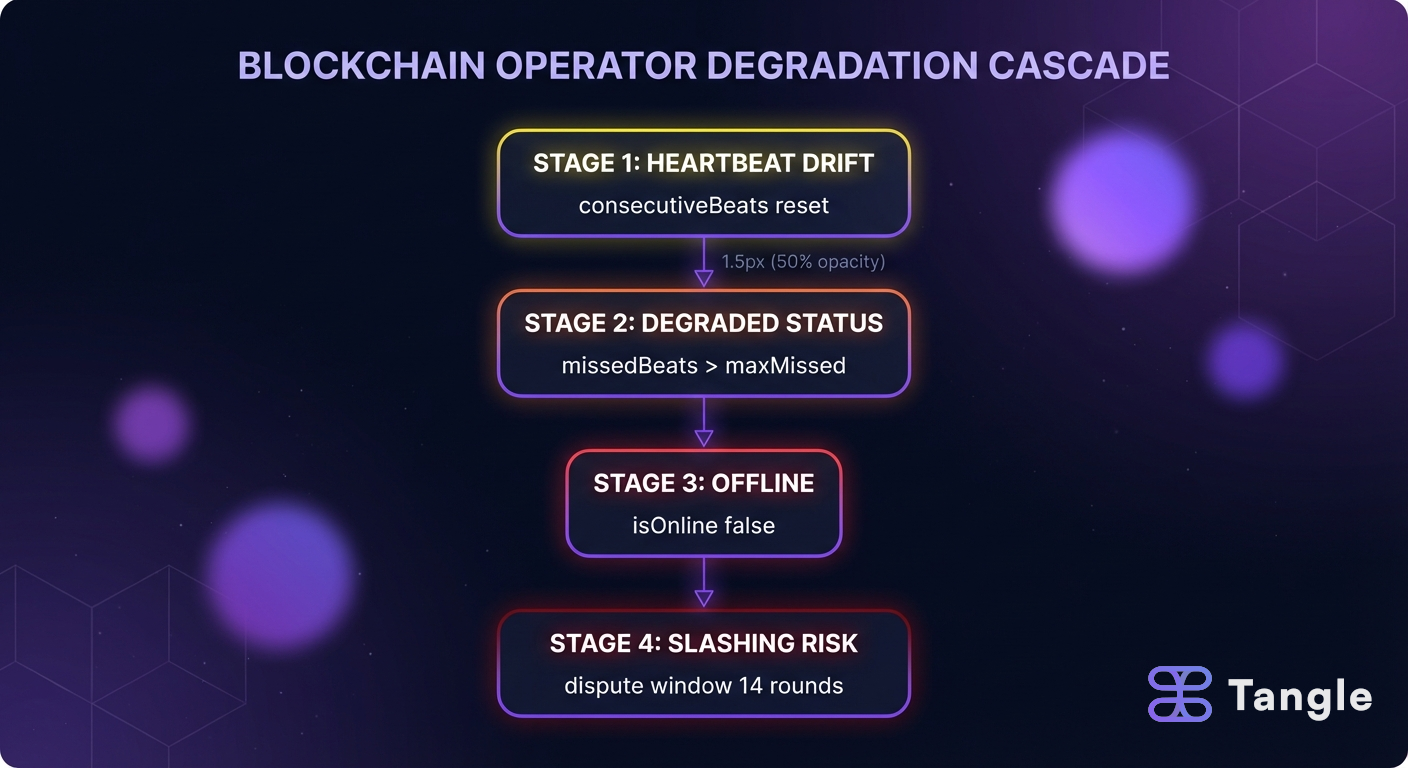
Stage 1: Heartbeat drift. Your heartbeat interval starts slipping. Maybe a network issue, maybe resource contention on the node. The consecutiveBeats counter resets and missedBeats starts climbing. On-chain, your status is still Healthy, but the trend is visible.
Stage 2: Degraded status. Once missedBeats crosses a threshold (per your service’s HeartbeatConfig.maxMissed), the status shifts to Degraded. You’re still potentially selectable for jobs, but the underlying issue is likely affecting job execution too.
Stage 3: Offline. Continued misses push the status to Offline. isOnline() returns false. You stop receiving work entirely. You’re still staked, still committed, but earning nothing.
Stage 4: Slashing risk. If the offline period extends beyond the grace window, slashing becomes possible. ProtocolConfig.sol defines DISPUTE_WINDOW_ROUNDS = 14 (3.5 days at 6-hour rounds), while SlashingLib defaults to a 7-day dispute window. An exit takes 56 rounds (14 days). These are not fast processes, which is intentional: they give operators time to recover from legitimate outages.
Every stage before slashing is recoverable. Fix the underlying issue, submit a successful heartbeat, and the cascade resets. The operators who get slashed are the ones who aren’t watching.
What metric violations actually do
The MetricDefinition system lets services define bounds (minValue, maxValue) for custom metrics like CPU utilization or memory usage. When a submitted metric falls outside those bounds, the violation is logged on-chain. Currently, violations don’t trigger automatic slashing. They create an on-chain record that can be used in governance-driven disputes, but the enforcement path is manual. This may change as the protocol matures, so treat metric bounds as soft limits today and hard limits tomorrow.
Revenue: what you’re protecting
The default fee split for job revenue is:
| Recipient | Share |
|---|---|
| Operators | 40% |
| Developers | 20% |
| Protocol | 20% |
| Stakers | 20% |
These percentages are governance-configurable (defined in TangleStorage.sol). On top of job revenue, operators can earn TNT incentives from the InflationPool and commission from delegator RewardVaults. But all of these revenue streams depend on one thing: staying in rotation. An operator that’s offline or has expired quotes earns nothing.
Building your monitoring stack
The QoS endpoints on your node give you the raw signals:
# Quick health check
curl -s http://localhost:9090/health
# Prometheus metrics (for Grafana dashboards)
curl -s http://localhost:9090/metrics | head -n 20This Prometheus alerting config catches problems at Stage 1 of the degradation cascade, before they affect job selection:
groups:
- name: blueprint_operator
rules:
- alert: HeartbeatDrift
expr: increase(operator_missed_beats_total[30m]) > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Operator {{ $labels.instance }} missed >2 heartbeats in 30m"
description: "Heartbeat drift detected. Investigate before status degrades."The metrics you should alert on:
Heartbeat health:
consecutiveBeatstrending downwardmissedBeatsincrementing- Status code changing from 0 to anything else
Quote freshness:
- Quote generation latency approaching
quote_validity_duration_secs - Expired-quote rate (track client-side 402 retries if possible)
- Benchmark cache age (stale benchmarks produce stale prices)
The protocol’s timing constants give you the boundaries for alert thresholds:
| Constant | Value | What it means for alerting |
|---|---|---|
ROUND_DURATION_SECONDS | 21,600 (6 hr) | Rounds are the unit of protocol time |
ROUNDS_PER_EPOCH | 28 (7 days) | Epoch boundaries trigger reward distribution |
DISPUTE_WINDOW_ROUNDS | 14 (3.5 days) | Time to respond to slashing disputes |
OPERATOR_DELAY_ROUNDS | 56 (14 days) | Minimum exit timeline |
MAX_QUOTE_AGE | 1 hour | Absolute ceiling for quote validity |
MIN_SERVICE_TTL | 1 hour | Shortest allowed service commitment |
FAQ
How many heartbeats can I miss before getting slashed?
There is no single fixed number. Slashing risk comes from a cascade, not a threshold: missed beats push you to Degraded, then Offline, then into a slashing-eligible window. Your service’s HeartbeatConfig.maxMissed setting controls when the Degraded transition happens, and that value varies by blueprint. The practical answer: set up alerts on missedBeats incrementing (Stage 1 of the cascade) and you’ll catch drift long before slashing is on the table.
Should I set my quote lifetime to the maximum 1 hour?
Almost certainly not. The 1-hour MAX_QUOTE_AGE is a protocol ceiling, not a recommendation. A 1-hour quote locks you into pricing that may not reflect current resource costs or token exchange rates. The 5-minute default is a reasonable starting point. Only extend it if your users consistently need more time to complete the quote-to-submission flow, and even then, 10-15 minutes is usually sufficient.
Do metric violations lead to automatic slashing?
Not currently. When a submitted metric falls outside the bounds defined in MetricDefinition, the violation is logged on-chain but enforcement is governance-driven, not automatic. That said, the on-chain record exists and could be used against you in a dispute. Treat metric bounds as constraints you should respect, because the enforcement mechanism will likely tighten over time.
What’s the dispute window for slashing?
ProtocolConfig.sol defines DISPUTE_WINDOW_ROUNDS = 14, which works out to 3.5 days at the current 6-hour round duration. However, SlashingLib defaults to a 7-day dispute window. The effective window depends on which value the governance configuration selects. Either way, it’s measured in days, not hours. You have time to respond, but only if you’re monitoring for the dispute in the first place.
Build with Tangle | Website | GitHub | Discord | Telegram | X/Twitter