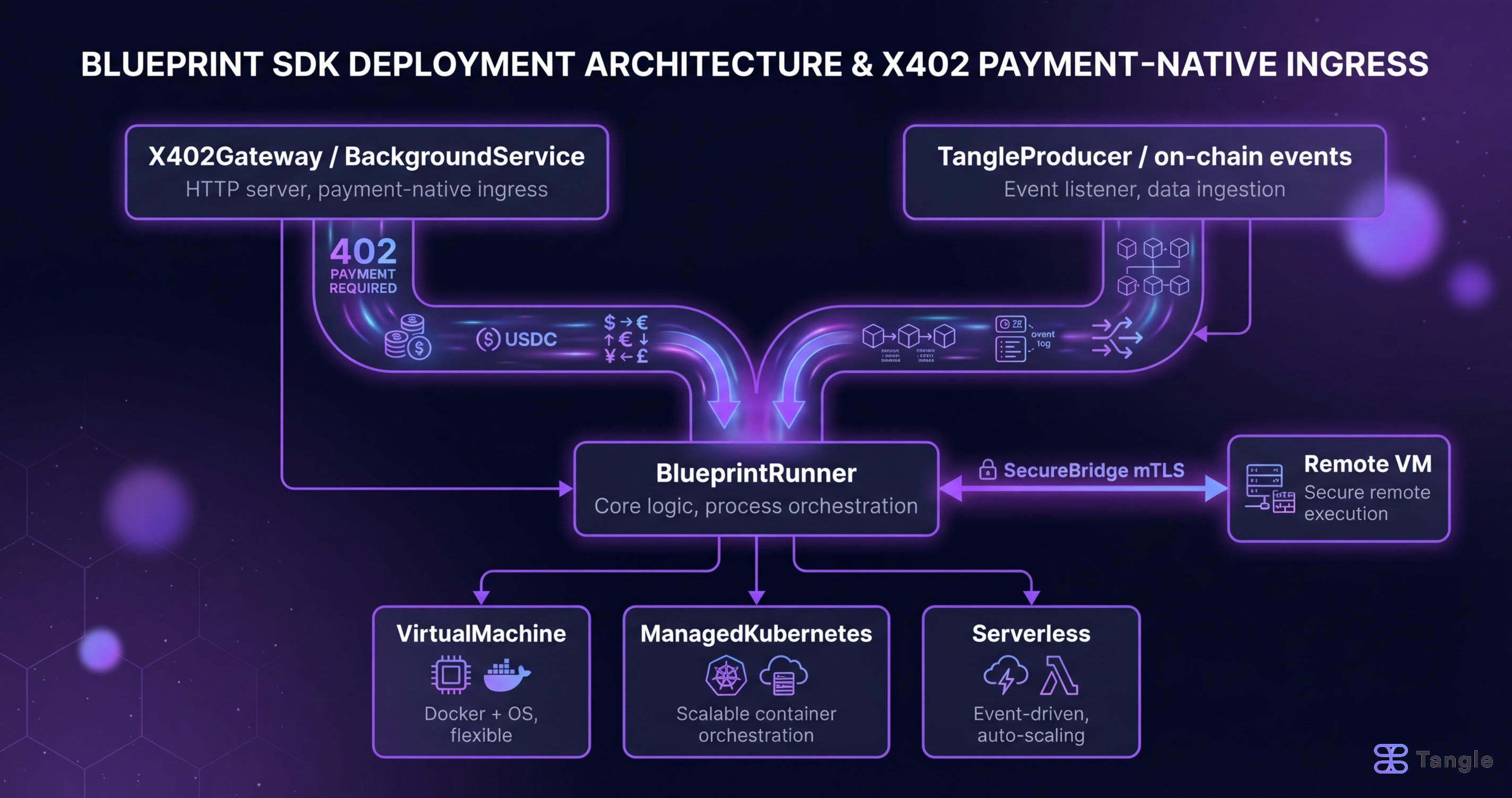
When you build a service with the Blueprint SDK, your service logic runs inside a BlueprintRunner. The runner manages all the ways work arrives: from the Tangle blockchain, from direct HTTP calls, or from any custom source you wire in. Where that runner actually executes, whether on your laptop, a cloud VM, or a Kubernetes cluster, is a separate decision called the deployment target.
This post explains how deployment targets work, how Blueprint services receive payment-gated HTTP jobs via the x402 protocol, and how those two concerns fit together across every topology Blueprint supports. If you have never heard of Blueprint or x402: Blueprint is Tangle’s SDK for building AI agent services that accept jobs from the Tangle network. x402 is a payment protocol built on HTTP 402, which lets HTTP clients pay for a request before the server executes it.
The key design choice this post is really about: the x402 payment gateway is not a separate proxy that sits in front of your service. It runs as a concurrent background task inside the same process as your job runner. That decision has real consequences for how you deploy, scale, and upgrade paid services, and the rest of this post explains why it was made that way and what it means for each deployment target.
What Problem Does This Solve?
Most infrastructure guides treat deployment and payment as separate concerns: pick a deployment target, then bolt on monetization later. A conventional payment gateway sits in front of compute. Request arrives, payment is checked, then compute runs. The payment layer can only see requests that arrive through it. When it goes down, nothing runs. When you want to add a second job source (say, on-chain Tangle events alongside HTTP payments), you need a multiplexing layer that the gateway does not natively provide.
Blueprint inverts this. The runner is the multiplexer. TangleProducer, X402Producer, and any other producers you wire in are concurrent streams feeding the same Router. Each producer is independent. The x402 payment HTTP server runs as a BackgroundService alongside heartbeats, metrics servers, and TEE auth services. It is structurally identical to those, just one more concurrent task in the runner’s lifecycle.
How Do You Deploy a Blueprint Service to Production?
What Is a Deployment Target?
Blueprint’s remote provider crate models deployment topology as an enum. From crates/blueprint-remote-providers/src/core/deployment_target.rs:
pub enum DeploymentTarget {
/// Deploy to virtual machines via SSH + Docker/Podman
VirtualMachine {
runtime: ContainerRuntime,
},
/// Deploy to managed Kubernetes service
ManagedKubernetes {
cluster_id: String,
namespace: String,
},
/// Deploy to existing generic Kubernetes cluster
GenericKubernetes {
context: Option<String>,
namespace: String,
},
/// Deploy to serverless container platform
Serverless {
config: std::collections::HashMap<String, String>,
},
}
pub enum ContainerRuntime {
Docker,
Podman,
Containerd,
}Two helper methods on DeploymentTarget make the operational distinctions precise:
pub fn requires_vm_provisioning(&self) -> bool {
matches!(self, Self::VirtualMachine { .. })
}
pub fn uses_kubernetes(&self) -> bool {
matches!(
self,
Self::ManagedKubernetes { .. } | Self::GenericKubernetes { .. }
)
}VirtualMachine is the only target that triggers SSH provisioning. Both Kubernetes variants get kubectl-based deployment. Serverless is a platform-specific escape hatch backed by a HashMap<String, String> for whatever the target platform requires.
The DeploymentConfig builder methods make the intended usage explicit:
// VM: provision a Hetzner node, SSH in, run Docker
DeploymentConfig::vm(CloudProvider::BareMetal(vec!["95.216.8.253".into()]), "eu-central".into(), ContainerRuntime::Docker)
// Managed K8s: EKS cluster, blueprint-ns namespace
DeploymentConfig::managed_k8s(CloudProvider::AWS, "us-east-1".into(), "my-eks-cluster".into(), "blueprint-ns".into())
// Generic K8s: existing cluster, optional context switch
DeploymentConfig::generic_k8s(Some("staging-context".into()), "blueprint-remote".into())What Is a Cloud Provider and Why Does It Matter for Networking?
CloudProvider is defined in crates/pricing-engine/src/types.rs and re-exported throughout the remote provider crate:
pub enum CloudProvider {
AWS,
GCP,
Azure,
DigitalOcean,
Vultr,
Linode,
Generic,
DockerLocal,
DockerRemote(String),
BareMetal(Vec<String>),
}DockerLocal is the development boundary. When this provider is selected, the runner executes containers on the host directly. No provisioning, no TLS tunnel, no remote endpoint registration. It is what you use during local development and integration testing.
The requires_tunnel extension method (from crates/blueprint-remote-providers/src/core/remote.rs) makes the network topology consequence explicit:
fn requires_tunnel(&self) -> bool {
matches!(
self,
CloudProvider::Generic | CloudProvider::BareMetal(_) | CloudProvider::DockerLocal
)
}Generic, BareMetal, and DockerLocal require a tunnel for private networking because they do not have managed load balancers. AWS, GCP, Azure, DigitalOcean, Vultr, and Linode get LoadBalancer or ClusterIP service types from the managed Kubernetes provider, so they do not need one.
For CloudConfig, the top-level credentials structure, provider credentials are loaded from environment variables with priority ordering. From crates/blueprint-remote-providers/src/config.rs:
pub struct CloudConfig {
pub enabled: bool,
pub aws: Option<AwsConfig>, // priority 10
pub gcp: Option<GcpConfig>, // priority 8
pub azure: Option<AzureConfig>, // priority 7
pub digital_ocean: Option<DigitalOceanConfig>, // priority 5
pub vultr: Option<VultrConfig>, // priority 3
}Priority is embedded in each provider config. When multiple providers are configured, higher-priority providers are preferred for deployment decisions.
How Does SecureBridge Handle mTLS for Remote Execution?
When a Blueprint job runs on a remote VM or remote Docker host, the manager needs a secure authenticated tunnel to that instance. That is SecureBridge in crates/blueprint-remote-providers/src/secure_bridge.rs.
The endpoint data structure:
pub struct RemoteEndpoint {
pub instance_id: String, // cloud instance ID
pub host: String, // hostname or IP
pub port: u16, // blueprint service port
pub use_tls: bool, // TLS for this connection
pub service_id: u64,
pub blueprint_id: u64,
}SecureBridgeConfig defaults to mTLS on:
impl Default for SecureBridgeConfig {
fn default() -> Self {
Self {
enable_mtls: true,
connect_timeout_secs: 30,
idle_timeout_secs: 300,
max_connections_per_endpoint: 10,
}
}
}In production (BLUEPRINT_ENV=production), certificate presence is enforced. The bridge fails hard if BLUEPRINT_CLIENT_CERT_PATH, BLUEPRINT_CLIENT_KEY_PATH, or BLUEPRINT_CA_CERT_PATH do not resolve to valid PEM files. In development, it falls back to system certs with a warning. Disabling mTLS entirely fails in production:
if is_production {
return Err(Error::ConfigurationError(
"mTLS cannot be disabled in production environment".into(),
));
}There is also SSRF protection on endpoint registration. Endpoints that resolve to public IPs are rejected. Only loopback and private ranges are accepted:
fn validate_endpoint_security(endpoint: &RemoteEndpoint) -> Result<()> {
if let Ok(ip) = host.parse::<std::net::IpAddr>() {
match ip {
std::net::IpAddr::V4(ipv4) => {
if !ipv4.is_loopback() && !ipv4.is_private() {
return Err(Error::ConfigurationError(
"Remote endpoints must use localhost or private IP ranges only".into(),
));
}
}
// ...
}
}
}This means SecureBridge is designed for tunneling to instances on private networks, not direct public internet exposure. The cloud provider’s network layer (VPC, private subnet, VPN) is the outer security boundary. SecureBridge handles authentication within that perimeter.
How Does the x402 Payment Gateway Deploy?
X402Gateway as a Background Service
X402Gateway implements BackgroundService. From crates/x402/src/gateway.rs:
impl BackgroundService for X402Gateway {
async fn start(&self) -> Result<oneshot::Receiver<Result<(), RunnerError>>, RunnerError> {
let (tx, rx) = oneshot::channel();
let router = self.build_router();
let addr = self.config.bind_address;
tokio::spawn(async move {
tracing::info!(%addr, "x402 payment gateway starting");
// ... GC task for expired quotes ...
let listener = tokio::net::TcpListener::bind(addr).await?;
axum::serve(listener, router).await
});
Ok(rx)
}
}The build_router method registers four route families:
Router::new()
.route("/x402/jobs/{service_id}/{job_index}", post(handle_job_request))
.route("/x402/health", get(health_check))
.route("/x402/stats", get(get_stats))
.route("/x402/jobs/{service_id}/{job_index}/auth-dry-run", post(post_auth_dry_run))
.route("/x402/jobs/{service_id}/{job_index}/price", get(get_job_price))POST /x402/jobs/{service_id}/{job_index} is the payment-gated execution endpoint. The X402Middleware intercepts this route: an absent payment header returns 402 with settlement options; a present header is verified via the facilitator and settlement completes before the handler runs.
GET /x402/jobs/{service_id}/{job_index}/price is the discovery endpoint. Clients call this first to learn what payment is required (network, token, amount) without triggering execution.
POST /x402/jobs/{service_id}/{job_index}/auth-dry-run lets callers check RestrictedPaid access control eligibility before spending a payment. Useful for wallets that want to show the user whether they are permitted before presenting the payment UI.
GET /x402/stats exposes the GatewayCounters snapshot: accepted payments, policy denials, replay guard hits, enqueue failures. Low-overhead observability without external instrumentation.
The x402 server binds to a separate address from any primary runner ports (default 0.0.0.0:8402), configured in X402Config.bind_address.
How Payments Become Job Calls
The mechanical connection between the HTTP server and the job runner is X402Producer. From crates/x402/src/producer.rs:
pub struct X402Producer {
rx: mpsc::UnboundedReceiver<VerifiedPayment>,
}
impl X402Producer {
pub fn channel() -> (Self, mpsc::UnboundedSender<VerifiedPayment>) {
let (tx, rx) = mpsc::unbounded_channel();
(Self { rx }, tx)
}
}
impl Stream for X402Producer {
type Item = Result<JobCall, BoxError>;
fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
match self.rx.poll_recv(cx) {
Poll::Ready(Some(payment)) => Poll::Ready(Some(Ok(payment.into_job_call()))),
Poll::Ready(None) => Poll::Ready(None),
Poll::Pending => Poll::Pending,
}
}
}X402Gateway::new creates both sides of this channel internally:
pub fn new(
config: X402Config,
job_pricing: HashMap<(u64, u32), U256>,
) -> Result<(Self, X402Producer), X402Error> {
// ...
let (producer, payment_tx) = X402Producer::channel();
// ...
Ok((gateway, producer))
}The payment_tx sender lives inside the gateway. When a payment verifies and settles, the handler sends a VerifiedPayment through payment_tx. The X402Producer (which holds rx) is wired into the runner as a standard producer. The runner polls it alongside TangleProducer or any other source.
VerifiedPayment.into_job_call() stamps the resulting JobCall with metadata that job handlers can inspect:
pub const X402_QUOTE_DIGEST_KEY: &str = "X-X402-QUOTE-DIGEST";
pub const X402_PAYMENT_NETWORK_KEY: &str = "X-X402-PAYMENT-NETWORK";
pub const X402_PAYMENT_TOKEN_KEY: &str = "X-X402-PAYMENT-TOKEN";
pub const X402_ORIGIN_KEY: &str = "X-X402-ORIGIN";
pub const X402_SERVICE_ID_KEY: &str = "X-TANGLE-SERVICE-ID";
pub const X402_CALL_ID_KEY: &str = "X-TANGLE-CALL-ID";
pub const X402_CALLER_KEY: &str = "X-TANGLE-CALLER";The job handler receives a JobCall identical in shape to one from Tangle, but the metadata tells it the call came from x402 and on which chain. Nothing in the dispatch path treats x402 jobs differently. The router does not know or care.
When Should You Use RestrictedPaid Access Control?
Each job’s x402 accessibility is independently configured via X402InvocationMode. From crates/x402/src/config.rs:
pub enum X402InvocationMode {
#[default]
Disabled,
PublicPaid,
RestrictedPaid,
}Disabled (the default) means the gateway will return 403 for this job even if payment is provided. The job is not reachable via x402. PublicPaid is open to anyone who can pay. RestrictedPaid adds an isPermittedCaller check against a Tangle contract before execution.
For RestrictedPaid, X402CallerAuthMode determines how caller identity is asserted:
pub enum X402CallerAuthMode {
#[default]
PayerIsCaller,
DelegatedCallerSignature,
PaymentOnly, // invalid for RestrictedPaid -- config validation rejects this
}PayerIsCaller infers identity from the settled payment’s payer address. It is the simplest option and works for wallets that pay for themselves. DelegatedCallerSignature supports scenarios where an agent pays on behalf of a user: the agent includes X-TANGLE-CALLER, X-TANGLE-CALLER-SIG, X-TANGLE-CALLER-NONCE, and X-TANGLE-CALLER-EXPIRY headers. The gateway verifies the signature and runs the Tangle permission check against the declared caller, not the payer.
RestrictedPaid requires both tangle_rpc_url and tangle_contract in the JobPolicyConfig. Config validation rejects RestrictedPaid with PaymentOnly auth or missing RPC config at startup.
What Does the Full Builder Pattern Look Like?
Here is how these pieces compose in BlueprintRunner. From crates/runner/src/lib.rs:
pub fn background_service(mut self, service: impl BackgroundService + 'static) -> Self {
self.background_services.push(DynBackgroundService::boxed(service));
self
}
pub fn producer<E>(
mut self,
producer: impl Stream<Item = Result<JobCall, E>> + Send + Unpin + 'static,
) -> Self { ... }The x402 wiring:
let config = X402Config::from_toml("x402.toml")?;
let job_pricing = /* HashMap<(u64, u32), U256> from your pricing config */;
let (gateway, producer) = X402Gateway::new(config, job_pricing)?;
BlueprintRunner::builder(tangle_config, env)
.router(router)
.producer(tangle_producer) // on-chain job source
.producer(producer) // x402 payment job source
.background_service(gateway) // x402 HTTP server
.run()
.await?;Both producers are polled concurrently in the same event loop. The gateway runs in its own tokio::spawn. The runner manages their lifetimes uniformly. When the runner shuts down, the oneshot::Receiver from each background service’s start() signals completion or error.
Which Deployment Target Should You Use?
| Target | Use it when | Ingress path | Proof boundary |
|---|---|---|---|
DockerLocal | You are testing handlers, pricing, and payment headers on one machine | Local gateway binds next to the runner | Process logs and local config only; no remote endpoint registration |
VirtualMachine | One operator wants a durable production runner without Kubernetes | Provider network reaches the gateway; SecureBridge handles manager-to-VM traffic | mTLS certificates plus private IP validation protect remote execution |
ManagedKubernetes | You need multiple pods, rollouts, and provider-managed load balancing | Service or ingress routes x402 traffic to pods that run the gateway | Kubernetes rollout state plus runner health determine promotion readiness |
GenericKubernetes | You already operate a cluster or need staging/on-prem parity | Existing kube context and your tunnel/network layer route to the gateway | Cluster policy is yours; Blueprint only owns runner lifecycle |
BareMetal | You control physical or leased hosts and accept SSH-based operations | Host networking exposes the gateway; SecureBridge authenticates private endpoints | Host inventory, cert rotation, and endpoint registration are the operational risk |
DockerLocal, no SecureBridge: Development. No provisioning, no TLS tunnel, no external cloud credentials needed. Run cargo run locally, test x402 payment flow with a local facilitator.
VirtualMachine (AWS, GCP, DigitalOcean, Vultr, Hetzner) with SecureBridge mTLS: Production single-operator. The manager SSHes into provisioned VMs, starts containers, and registers RemoteEndpoint in SecureBridge. The x402 gateway binds on the remote VM and is reachable via the provider’s networking. SecureBridge handles manager-to-instance communication authenticated with client certs from /etc/blueprint/certs/.
ManagedKubernetes (EKS, GKE, AKS) with CloudProvider load balancer: Multi-job, horizontally scaled. EKS and AKS get LoadBalancer service type. GKE gets ClusterIP with an Ingress resource. The x402 gateway runs as a BackgroundService inside each pod. Payment ingress is co-located with the job runner, not a separate service.
GenericKubernetes with tunnel: Existing clusters, staging environments, or on-prem. The context: Option<String> field lets you switch kubeconfig contexts without modifying the default. Paired with CloudProvider::Generic, which requires_tunnel(). You handle the private networking layer yourself.
BareMetal: Bare metal SSH hosts. The BareMetal(Vec<String>) variant takes a list of SSH-accessible hosts. Also requires_tunnel(). No managed networking. SecureBridge provides the auth layer within your existing network perimeter.
The x402 gateway placement is the same in all of these: .background_service(gateway) in the builder. The deployment target changes where the process runs and how it is networked. The payment ingress layer is identical code regardless of where the runner executes.
What Are the Tradeoffs of This Design?
The BackgroundService model solves a real operational problem: operator upgrade paths do not require payment gateway downtime. When you roll a new version of your blueprint, the runner and its BackgroundServices restart together. There is no separately managed payment proxy to upgrade, no version skew between the proxy and the business logic it fronts.
It also means x402 payment ingress scales with your runner. Add more pods and you get more payment capacity. No centralized payment router to scale separately, no single point of failure in the payment path.
The tradeoff is that the x402 HTTP endpoint is co-located with the job runner rather than edge-deployed. If you need CDN-level caching of price discovery responses or geographic distribution of payment ingress endpoints, you would put a lightweight HTTP proxy in front. The price and auth-dry-run endpoints are stateless and safe to cache. The job execution endpoint requires the live runner. That one cannot be edge-cached by definition.
For most Blueprint service operators, particularly ones using Tangle for decentralized AVS infrastructure, the co-location model is the right default. The runner is already the first layer worth scaling. Adding another independent service to manage introduces complexity that only pays off at scales most early-stage services will not hit.
FAQ
Should x402 run as a separate proxy in front of the Blueprint runner?
Not by default. In the Blueprint SDK design, X402Gateway runs as a BackgroundService in the same runner process that handles on-chain jobs. That keeps payment-gated HTTP jobs, Tangle jobs, health checks, and shutdown behavior under one lifecycle. Put a proxy in front only when you need CDN routing, edge TLS termination, or provider-specific ingress controls.
Which deployment target should a first production operator choose?
Use VirtualMachine when you want the smallest production surface: one durable host, SecureBridge mTLS, and a single runner process. Use managed Kubernetes when you already need rolling deploys, pod autoscaling, and provider load balancers. Use DockerLocal only for local tests and integration loops.
What has to be private in a remote provider deployment?
SecureBridge expects remote execution endpoints to resolve to loopback or private IP ranges. Public exposure belongs at the x402 HTTP ingress layer or a controlled load balancer, not at the manager-to-instance execution channel. Treat private networking, certificate rotation, and endpoint registration as one deployment boundary.
Where should I look for the underlying standards?
Start with the x402 protocol repository, the Kubernetes service model, and the TLS client authentication guidance in RFC 8446. For the Tangle-side implementation, read the Blueprint SDK source and the previous post on operator economics.
S2-09 in the x402 Production Runway series. Previous: Operator Economics and Fee Distribution.